Enterprise Datenplattform mit Databricks Part 2
Einführung
Willkommen zurück zu unserer Blog-Serie rund um den Aufbau moderner Enterprise-Datenplattformen!
In Teil 1 unserer Serie haben wir die strategischen und architektonischen Grundlagen einer zukunftsfähigen Cloud-Datenplattform beleuchtet. Heute tauchen wir tiefer in die technische Umsetzung des ersten und wichtigsten Schrittes ein: die Ingestion.
In der klassischen Enterprise-Welt werden oft mächtige, jedoch starre Ingestion-Tools genutzt. Im Gegensatz dazu setzen wir beim Aufbau moderner Cloud-Plattformen auf maximale Flexibilität und Skalierbarkeit durch die Kombination aus der Python-Standardbibliothek requests und der Rechenleistung von Apache Spark.
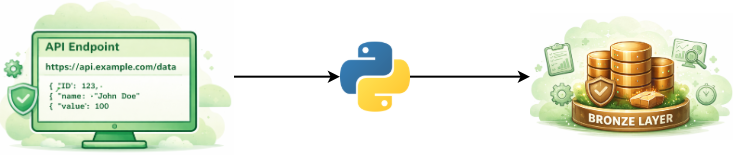
Visualisierung erstellt mit Unterstützung von KI (Gemini)
Ingestion
Viele Enterprise-APIs erfordern eine komplexe Logik für Authentifizierung, Fehlerbehandlung und Pagination. Um diese Herausforderungen zu bewältigen und API-Calls vollumfänglich steuern zu können, nutzen wir die Flexibilität von Python. Die Vorteile davon liegen auf der Hand:
- Intelligente Pagination: Metadaten wie X-Pages können dynamisch aus den API-Headern ausgelesen werden. Dadurch kann die exakte Datenmenge erkannt und die Folgeseiten-Abfrage präzise gesteuert werden.
- Maßgeschneiderte Resilienz: Robustes Error-Handling kann direkt im Code implementiert werden. Wir unterscheiden strikt zwischen temporären Fehlern (z.B.: 503: Service unavailable) mit einer automatischen Retry-Logik und kritischen Fehlern (z.B.: 401: Unauthorized), die einen sauberen Abbruch inklusive Alarmierung auslösen.
- Open Source & Kosteneffizienz: Durch den Einsatz von Python setzen wir in diesem Fall auf Open Source statt auf herstellerabhängige Lizenzmodelle. Es entstehen keine zusätzlichen Kosten durch Drittanbieter-Tools, wodurch lediglich die ohnehin vorhandenen Compute-Kosten innerhalb von Databricks anfallen. Zudem vermeiden wir einen Vendor Lock-in: Der Ingestion-Code ist portabel, transparent und bleibt vollständig unter unserer Kontrolle.
Der technologische Brückenschlag erfolgt durch die Konvertierung der kurzlebigen API-Daten in die verteilte Architektur von Databricks. Wir konvertieren die JSON Daten in einen Spark DataFrame, wodurch die Informationen für die parallele Verarbeitung auf dem Cluster zugänglich gemacht werden.
In diesem Prozessschritt nutzen wir die Flexibilität von Spark zudem für minimale technische Aufbereitung, wie etwa das Hinzufügen eines ingested_at Zeitstempel, das Bereinigen von Feldnamen, die Typkonvertierung kritischer Attribute oder das Filtern offensichtlicher Duplikate, um bereits im Bronze-Layer eine valide Datenbasis für die nachfolgende Fachlogik zur Verfügung zu stellen.
Die finale Persistierung des Spark Dataframes erfolgt im Delta-Format innerhalb des Bronze-Layers, dem modernen Standard für Enterprise-Lakehouses. Im Gegensatz zu herkömmlichen Dateiformaten bietet Delta Lake volle ACID-Transaktionssicherheit: Schreibvorgänge sind damit entweder vollständig erfolgreich oder werden bei Fehlern komplett zurückgerollt, was einen essentiellen Schutz gegen Datenkorruption darstellt.
Ein entscheidender Vorteil des Delta-Formats ist das Time Travel Feature, welches eine lückenlose Historisierung ermöglicht und uns erlaubt, jederzeit auf vergangene Datenstände zurückzugreifen. Darüber hinaus wird die Performance von Abfragen durch ein automatisiertes Indexing massiv optimiert.
Ausblick
Die Rohdaten sind nun sicher im Bronze-Layer gelandet, doch wie machen wir daraus veredelte, business-ready Informationen?
Im kommenden dritten Teil unserer Serie widmen wir uns der Medaillon-Architektur mit dbt (data build tool). Wir zeigen, wie wir Datentransformationen im Silver- und Gold-Layer agil, transparent und mit modernsten Software-Engineering-Best-Practices (wie Version Control und automatisiertem Testing) umsetzen.
Bleibt dran!